In a recent DataFramed podcast, Hugo Bowne-Anderson and Jonathan Nolis discuss whether data scientist teams should be centralized or distributed. I have my own opinions about that question.
Should data science teams be centralized or distributed?
I was happy to find that Jonathan Nolis has the same opinion as I do: that a data science team works best when distributed into client areas. In addition, we agree that if you distribute your data science team among several different client areas, you have to find a way of keeping the data scientists feeling as if they’re part of a cohesive group. And that’s hard.
For me, a key part of the argument to distribute data scientists in client areas relies on Drew Conway’s (ancient) Data Science Venn diagram.
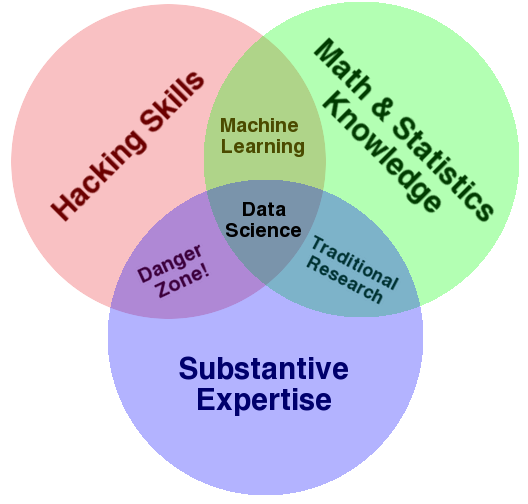
Assigning data scientists to a client area will help build the “Substantive Expertise” part of the diagram. A common trap here is “Well, we can do the same if we keep the data scientists centralized and give them specializations that match the client areas.”
Although I think that can work, I worry about what happens when data scientists have downtime.
Incentives for client areas and centralized data science teams
In my observations (low sample size), the client areas usually have a better sense of ROI1 - if they invest resources on something, they expect returns. On the other hand, most centralized data science teams I’ve seen have two problems: data scientists hired without a clear purpose and an incentive to overengineering: a current example is to use Deep Learning where a regression would do.

It may be simply that client areas are more mature and battle worn than centralized data science groups, at least in my experience. I think that if a data scientist is assigned to a client area and there’s downtime, they’ll put the data scientist to work in business intelligence or decision analysis. On the other hand, if the data scientist is assigned to a centralized data science group, they’ll be pulled into a project away from their “client area specialization” or will find a way to work in something novel that’s cool (as of 2018, autoencoders, GANs or something with “Bayesian” in its name).
And here the ROI appears again: as the data scientist works through the BI project, they’ll learn more about the data and more about the business and its data, and that investment has a large likelihood of return in their next project in the same group. Whereas if they spend this time learning a new technique, the return is uncertain.
But wait, if you do that, data scientists will never learn something new
Here’s where the hard part of keeping a data scientist community pays off. That community may be weekly “Lunch & Learns” if the number of data scientists is small, or quarterly conferences if the number of data scientists is very big and your company is very, very rich.
If you don’t forcefully push towards having such a community, it’s very likely that data scientists will reinvent the wheel over and over again, and if their time is as precious as their high salary indicates, that will be a waste of money. For example, if you have 5 data scientists It’s better to spend $50k on travel to bring them together a few times a year than to have one of them wasting three months reinventing something that another of them already done.
Where I disagree with Jonathan Nolis
In the podcast, Jonathan suggests that the data scientists should be assigned to client areas and report “solid line” to a Chief Data Scientist, while reporting “dotted line” to the client areas. I would do the opposite. However, listening to the podcast, it seems that Jonathan didn’t have a strong opinion that one is better than the other, and again in agreement, neither do I.
One big advantage of having a “solid line” group of data scientists is career advancement. It’s easier to compare data scientists with other data scientists. Leaving them in the client areas will require to compare them with other members of the client area, and they may be seen as wizards (and overvalued) or “too hard to understand”, and be undervalued.
One disadvantage is estimating the value of the data scientist to the client area. Data scientists that are more creative in their value calculations or less scrupulous are probably going to get ahead. I’ve lost count of the times that a data science project saved more revenue than the customer ever had.
So, what do I do?
Honestly, if you’re starting a data science team, your best bet is to hire someone like Jonathan or Drew Conway to plan the team for you. You’re going to spend a lot of money on Data Science, and it’s important to make sure that it will be well spent.
If you’re on a budget and all you can invest is the time to read some blog posts, well… you probably don’t have enough money to hire data scientists. But if you do, I recommend assigning them to the client areas and keeping them there. Even when they’re not doing modeling or machine learning, they’re learning more about the business and its data.